البيانات كأصل: DataFi تفتح آفاقاً جديدة في سوق غير مستكشَف
“نعيش اليوم في عصر تتسابق فيه القوى العالمية لبناء أفضل نماذج الذكاء الاصطناعي الأساسية. فمع أهمية القدرة الحاسوبية والهندسة البرمجية، تكمن القيمة الحقيقية في بيانات التدريب.”
— سانديب تشينتشالي، الرئيس التنفيذي للذكاء الاصطناعي، Story
استكشاف آفاق قطاع بيانات الذكاء الاصطناعي: منظور من Scale AI
من أبرز مستجدات الذكاء الاصطناعي هذا الشهر، استعراض Meta لإمكاناتها المالية الضخمة، حيث يقود مارك زوكربيرغ حملة استقطاب مكثفة لبناء فريق Meta AI عالمي المستوى يضم نخبة من الباحثين الصينيين. يشرف على هذا التحول ألكسندر وانغ، المؤسس البالغ من العمر 28 عامًا لشركة Scale AI التي انطلقت من الصفر وتبلغ قيمتها الآن 29 مليار دولار. تخدم الشركة عملاء بارزين مثل الجيش الأمريكي وشركات منافسة بحجم OpenAI وAnthropic وMeta نفسها. تعتمد هذه الكيانات الرائدة جميعها على خدمات البيانات التي تقدمها Scale AI، إذ تتمحور أنشطتها حول تزويد النماذج الضخمة ببيانات مصنفة عالية الجودة وعلى نطاق واسع.
ما سر تميز Scale AI وانفرادها عن بقية شركات التقنية الواعدة؟
يكمن السر في وعيها المبكر بأهمية البيانات كمحور رئيسي في منظومة الذكاء الاصطناعي.
تشكل القدرة الحاسوبية، النماذج، والبيانات الأعمدة الرئيسة لمنظومة الذكاء الاصطناعي. فالنموذج يُشبه الجسد، والحوسبة هي الغذاء، أما البيانات فهي المعرفة والخبرة المتراكمة.
بعد بروز نماذج اللغة الضخمة، تغيرت أولويات القطاع من تصميم النماذج إلى تطوير بنية الحوسبة التحتية. فقد اعتمدت معظم النماذج الرائدة المحولات كأساس هندسي، مع مستجدات دورية مثل MoE أو MoRe. وتلجأ الشركات الكبرى لبناء عناقيد حوسبة فائقة أو توقيع عقود طويلة الأمد مع مزودين مثل AWS. وبعد ضمان البنية الحاسوبية، تحول التركيز إلى تصاعد أهمية البيانات.
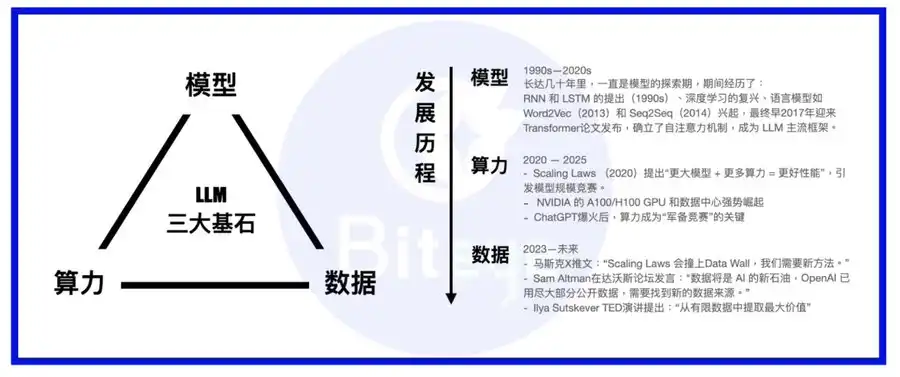
وعلى عكس شركات البيانات المؤسسية التقليدية مثل Palantir، كرست Scale AI جهودها لتأسيس قاعدة متينة للبيانات من أجل الذكاء الاصطناعي. فهي لا تكتفي بالاعتماد على مجموعات البيانات المتوفرة، بل تركز على إنتاج بيانات عالية الجودة وطويلة الأمد، وتوظف فرقًا من الخبراء البشريين للإشراف على تدريب البيانات وتحسين جودتها.
هل لديك شكوك في هذا النشاط التجاري؟ إليك كيف يتم تدريب النماذج فعليًا.
يمر تدريب النماذج الذكية بمرحلتين رئيسيتين: مرحلة ما قبل التدريب (Pre-training) ومرحلة الضبط الدقيق (Fine-tuning).
تشبه مرحلة ما قبل التدريب الطريقة التي يتعلم بها الطفل تحدث اللغة، إذ يقوم الذكاء الاصطناعي بابتلاع كميات ضخمة من النصوص والشيفرات المجمعة من الإنترنت لفهم اللغة الطبيعية وأساسيات التواصل.
أما الضبط الدقيق، فيحاكي التعليم المنهجي الرسمي، حيث توجد إجابات دقيقة وصحيحة. كما تصنع المناهج الطلاب، نعتمد مجموعات بيانات معدة خصيصًا لتدريب النماذج على مهارات أو أهداف معينة.

لذا، نحن بحاجة إلى نوعين من البيانات:
· بيانات تتطلب معالجة بسيطة—الكمية هي الأساس. عادة تأتي من منصات ضخمة لمحتوى المستخدمين (مثل Reddit وTwitter)، أو أرشيفات المؤلفات المفتوحة، أو مصادر خاصة بالشركات.
· ونوع يشبه الكتب الدراسية المتخصصة—يخضع لتصميم دقيق بهدف نقل قدرات أو معارف محددة، ويستلزم تنظيف البيانات وتصفيتها وتصنيفها ومراجعتها من قبل البشر.
يشكل هذان النوعان معًا العمود الفقري لسوق بيانات الذكاء الاصطناعي. وعلى الرغم من أن البيانات تبدو بسيطة تقنيًا، إلا أن الاتجاه السائد يرى أن البيانات ستصبح عامل التفوق الحاسم لدى مزودي النماذج الضخمة مع اقتراب حدود توسع البنية الحاسوبية.
ومع تطور النماذج، ستصبح الحاجة إلى بيانات تدريبية متخصصة ودقيقة شرطًا رئيسًا لتحقيق أداء متفوق. وبتوسيع التشبيه، إذا كان تدريب النموذج يشبه إعداد بطل في الفنون القتالية، فإن البيانات تشكل كتاب التدريب النهائي، بينما تمثل القدرة الحاسوبية جرعة السحر، ويبقى النموذج هو الموهبة الفطرية نفسها.
ومن زاوية استثمارية، تعتبر بيانات الذكاء الاصطناعي قطاعًا تراكميًا طويل الأمد، إذ تزداد قيمة الأصول البيانية بمرور الزمن مع تراكم الجهود المبكرة.
DataFi في Web3: البيئة المثالية لنمو بيانات الذكاء الاصطناعي
مقارنة بالقوى العاملة العالمية عن بُعد التي تعتمد عليها Scale AI في الفلبين وفنزويلا، يتمتع Web3 بميزات استثنائية في قطاع بيانات الذكاء الاصطناعي، من خلال مفهوم DataFi.
يبرز Web3 DataFi بعدة مزايا أساسية:
1. ملكية البيانات والخصوصية والأمان بعقود ذكية
مع بلوغ مصادر البيانات العامة حدها الأقصى، أصبحت الحاجة إلى بيانات جديدة وخاصة أمرًا جوهريًا، ما يفرض تساؤلًا حول الثقة: هل تبيع بياناتك لوسيط مركزي، أم تحتفظ بحقوقك عبر السلسلة وتستخدم العقود الذكية لتتبع كيفية استخدام بياناتك ووقت استخدامها وغاياتها بشفافية؟
في حالات البيانات الحساسة، تتيح التقنيات مثل براهين المعرفة الصفرية (Zero-Knowledge Proofs) وأجهزة البيئة التنفيذية الموثوقة (TEE) إمكانية الحفاظ على خصوصية المعلومات ومنع تسربها لأي طرف بشري.
2. ميزة التحكيم الجغرافي المدمجة: مشاركة موزعة تجذب أفضل المواهب حول العالم
يتطلب العصر الرقمي إعادة النظر في نماذج العمل التقليدية. فبدلًا من البحث المركزي عن عمالة رخيصة كما تفعل Scale AI، يتيح هيكل Web3 الموزع، إلى جانب الحوافز القائمة على العقود الذكية، لمواهب متنوعة من أنحاء العالم الإسهام ببياناتهم مقابل مكافآت عادلة وشفافة.
وعند تنفيذ مهام التصنيف أو التحقق من النماذج، تحقق هذه اللامركزية تنوعًا أكبر وتقلل من التحيز، ما يشكل ميزة تنافسية هامة في قطاع البيانات عالية الجودة.
3. حوافز وتسويات شفافة عبر البلوكشين
هل تريد تجنب العمليات غير الموثوقة؟ تضمن العقود الذكية على البلوكشين حوافز واضحة وشفافة تُنفذ تلقائيًا، مما يجعلها أكثر كفاءة من الأنظمة التقليدية المعتمدة على الإدارة اليدوية.
ومع تراجع مظاهر العولمة، لم يعد بالإمكان تحقيق أفضلية التكلفة الجغرافية عبر تأسيس شركات في كل مكان. تتيح التسويات على السلسلة تجاوز القيود وتسهيل المشاركة وصرف المستحقات عبر الحدود ببساطة وشفافية.
4. أسواق بيانات مفتوحة وفعالة لكل الأطراف
اقتطاع الوسطاء لنصيب من الأرباح يظل مشكلة مستمرة. وبديلاً عن الشركات المركزية، توفر المنصات القائمة على السلسلة أسواقًا شفافة شبيهة بمنصات التجارة الإلكترونية الكبرى تربط البائعين بالمشترين مباشرة، ما يعزز الكفاءة ويوفر جهد الوسطاء.
ومع تطور السوق وارتفاع الطلب على بيانات الذكاء الاصطناعي المتخصصة والمعقدة، سيظل السوق اللامركزي هو الحل القادر فعليًا على تلبية هذه الاحتياجات وتحقيق العوائد على نطاق واسع.
DataFi: المدخل اللامركزي الأكثر سهولة للذكاء الاصطناعي للمستخدمين الأفراد
رغم أن أدوات الذكاء الاصطناعي سهلت الانخراط، ولا يزال الذكاء الاصطناعي اللامركزي يعمل على كسر احتكار الشركات الكبرى، فإن الكثير من المشاريع ما زالت صعبة المنال على المستخدمين غير التقنيين. فغالبًا ما تتطلب المشاركة في شبكات الحوسبة اللامركزية تجهيزات مرتفعة التكلفة، كما تبدو أسواق النماذج المعقدة تحديًا بحد ذاتها.
في المقابل، يقدم Web3 فرصًا نادرة وسهلة المنال للمستخدمين العاديين وسط ثورة الذكاء الاصطناعي؛ إذ يكفي فقط ربط المحفظة الرقمية للبدء. بوسع المستخدم المساهمة ببياناته، أو تصنيف مخرجات النماذج بالاعتماد على خبرته أو حدسه، أو تقييم النماذج، أو استخدام أدوات الذكاء الاصطناعي البسيطة للأعمال الإبداعية والتداول—غالبًا بدون عوائق تقنية تذكر، خصوصًا لمن لديهم خبرة مع برامج الإيردروب.
أفضل مشاريع DataFi على Web3: متابعة وتحليل
حيثما تتدفق الأموال تتبلور التوجهات. فقد أثبتت صفقة Meta باستثمار 14.3 مليار دولار في Scale AI وقفزة سهم Palantir خمسة أضعاف حجمها، إمكانيات واعدة لـDataFi في Web2؛ أما على Web3 فقد أصبح DataFi من أسرع القطاعات نموًا في جذب التمويل. إليكم أبرز المشاريع:
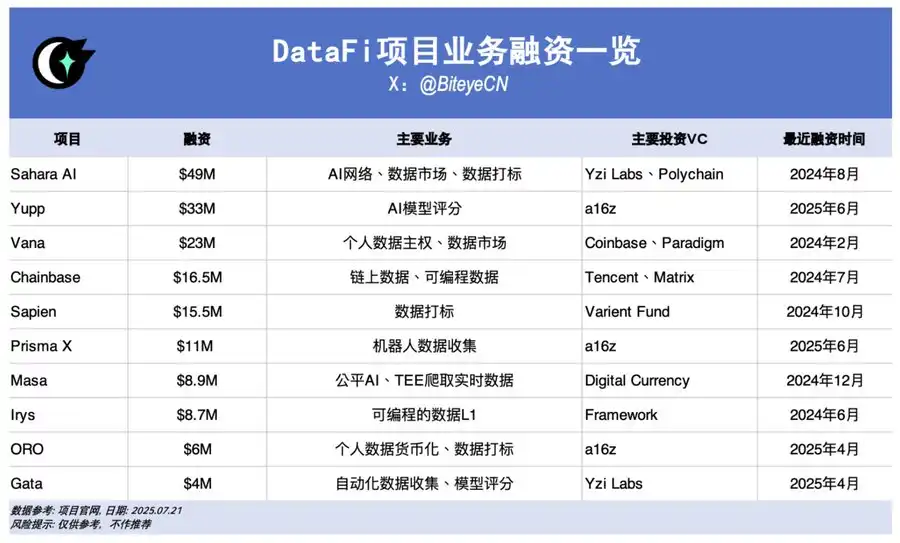
صحراء AI، @SaharaLabsAI، حصلت على تمويل 49 مليون دولار
تسعى Sahara AI لبناء بنية تحتية لامركزية فائقة وسوق بيانات متكاملة للذكاء الاصطناعي. تُطلق النسخة التجريبية لمنصة خدمات البيانات في 22 يوليو، مع منح المستخدمين مكافآت مقابل تقديم البيانات وتسمية العينات.
الرابط: app.saharaai.com
Yupp، @yupp_ai، تمويل 33 مليون دولار
Yupp منصة لتقييم مخرجات الذكاء الاصطناعي بمشاركة المستخدمين في مقارنة إجابات النماذج والتصويت للأفضل. يمكن تحويل نقاط المنصة إلى عملات مستقرة مثل USDC.
الرابط: https://yupp.ai/
Vana، @vana، تمويل 23 مليون دولار
يتيح Vana للمستخدمين تحويل بياناتهم الشخصية (سجل التصفح، النشاط الاجتماعي) إلى أصول رقمية، وتُجمَع البيانات في منظمات DAO ومجمعات سيولة بيانات مخصصة للتدريب على النماذج، مع مكافآت رمزية للمشاركين.
الرابط: https://www.vana.org/collectives
Chainbase، @ChainbaseHQ، تمويل 16.5 مليون دولار
تركز Chainbase على بيانات البلوكشين، حيث تنظّم وتحوّل أنشطة أكثر من 200 سلسلة إلى أصول قابلة للاستثمار لصالح مطوري تطبيقات DApp. وتعتمد في ذلك على نظام Manuscript وTheia AI. حاليًا المشاركة الفردية محدودة.
Sapien، @JoinSapien، تمويل 15.5 مليون دولار
تعتمد Sapien على تحويل المعرفة البشرية إلى بيانات تدريبية عالية الجودة للذكاء الاصطناعي، حيث يمكن لأي شخص المساهمة في تسمية البيانات، ويجري ضبط الجودة عبر تقنيات مراجعة الأقران، كما يُشجع نظام السمعة والرهن على المدى الطويل لضمان أعلى مكافآت.
الرابط: https://earn.sapien.io/#hiw
Prisma X، @PrismaXai، تمويل 11 مليون دولار
تطمح Prisma X إلى أن تكون طبقة التنسيق المفتوحة أمام الروبوتات، ويعد جمع البيانات الحسية أحد ركائزها. ما تزال في المراحل الأولى، ويمكن للمستخدمين المساهمة بدعم جمع بيانات الروبوتات أو إدارتها عن بُعد أو المشاركة في اختبارات لكسب النقاط.
الرابط: https://app.prismax.ai/whitepaper
Masa، @getmasafi، تمويل 8.9 مليون دولار
تتصدر Masa منظومة Bittensor من خلال شبكة البيانات ووكلاء البيانات الخاصة بها، وتتيح الشبكة الوصول الفوري إلى بيانات X/Twitter عبر أجهزة TEE. المشاركة الفردية حاليًا مكلفة ومعقدة.
Irys، @irys_xyz، تمويل 8.7 مليون دولار
يستهدف مشروع Irys توفير تخزين ومعالجة بيانات فعّالة وقليلة التكلفة للذكاء الاصطناعي وتطبيقات DApp. وعلى الرغم من محدودية فرص مشاركة المستخدمين، توفر النسخة التجريبية الحالية العديد من الفرص التفاعلية.
الرابط: https://bitomokx.irys.xyz/
ORO، @getoro_xyz، تمويل 6 ملايين دولار
يُمكن لأي شخص المساهمة في تطوير الذكاء الاصطناعي عبر ربط حساباته الاجتماعية أو الصحية أو المالية أو إنجاز مهام بيانات محددة. الشبكة التجريبية مفتوحة الآن للجميع.
الرابط: app.getoro.xyz
Gata، @Gata_xyz، تمويل 4 ملايين دولار
تقدم Gata طبقة بيانات لامركزية مع ثلاثة منتجات رئيسية: وكلاء بيانات يعملون عبر المتصفح، ودردشات متعددة لاختبار النماذج ومكافآت شبيهة بنموذج Yupp، وإضافة لجمع محادثات ChatGPT.
الرابط: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
ما معايير تقييم هذه المشاريع؟
العوائق التقنية أمام معظم هذه المشاريع ما تزال منخفضة، غير أن الاحتفاظ بالمستخدمين وتعزيز المنظومة البيئية يُحققان النمو المتسارع. يتطلب الفوز في سوق البيانات الاستثمار المبكر في الحوافز وتجربة المستخدم، فذلك وحده يجذب العدد الكافي للمشاركة الفاعلة.
ولأنها مشاريع تستند إلى العمل البشري، يتعين على منصات البيانات معالجة تحديات إدارة القوى العاملة وضمان جودة البيانات. يعاني العديد من مشاريع Web3 من هيمنة فئة “المزارعين”—الذين يسعون للربح القصير دون اعتبار للجودة—مما يؤثر سلبًا على كفاءة البيانات وثقة المشترين. ولهذا تعطي Sahara وSapien وغيرهما أولوية للجودة وبناء علاقات قوية وطويلة المدى مع المشاركين.
أما غياب الشفافية فيظل إشكالية—فمع تحدي “المثلث المستحيل” للبلوكشين ينطلق كثير من المشاريع بهياكل مركزية رغم بيئة Web3، فلا تظهر البيانات بوضوح على السلسلة، ولا تتضح الالتزامات تجاه الانفتاح، مما يهدد استدامة قطاع DataFi. نأمل أن يسرع القطاع وتيرته نحو الشفافية والالتزام بجذوره اللامركزية.
وأخيرًا، لا بد من مسارين لتحقيق انتشار DataFi: حشد المستخدمين الأفراد لتغذية منظومة البيانات وخلق اقتصاد مغلق للذكاء الاصطناعي، وضمان إقبال المؤسسات الكبرى التي تبقى المصدر الرئيس للإيرادات بالمرحلة الحالية. وهنا، حققت مشاريع Sahara AI وVana وغيرهما نجاحًا ملموسًا.
خاتمة
في المحصلة، يهدف DataFi إلى تسخير الذكاء البشري عبر أطر العقود الذكية لتطوير الذكاء الاصطناعي طويل الأمد، وضمان مكافأة الجهود البشرية، وبالتالي تمكين الأفراد من جني ثمار تطور الذكاء الاصطناعي.
لمن يشعر بالحيرة في عصر الذكاء الاصطناعي أو يواصل الإيمان بتقنية البلوكشين رغم تقلبات أسواق العملات الرقمية، تمثل المشاركة في DataFi خيارًا حكيمًا وملائمًا للمرحلة.
إخلاء مسؤولية:
- تمت إعادة نشر هذه المادة من [BLOCKBEATS] وتعود حقوقها للمؤلف الأصلي [anci_hu49074، مساهم أساسي في Biteye]. للاستفسار عن حقوق النشر، يرجى التواصل مع فريق Gate Learn لاتخاذ الخطوات النظامية المعتمدة.
- إخلاء مسؤولية: جميع الآراء الواردة للرأي الشخصي للكاتب ولا تعد نصيحة استثمارية.
- أنجز فريق Gate Learn ترجمة النسخ إلى لغات أخرى. لا يجوز إعادة نشر أو توزيع أو نسخ الترجمة دون إشارة واضحة إلى Gate.
مقالات ذات صلة

ما هو Tronscan وكيف يمكنك استخدامه في عام 2025؟

كل ما تريد معرفته عن Blockchain

ما هي كوساما؟ كل ما تريد معرفته عن KSM

ما هو كوتي؟ كل ما تحتاج إلى معرفته عن COTI

ما هي ترون؟
