データの資産化:DataFiが新たなブルーオーシャンを創出
「私たちは、世界が基盤となる最先端のAIモデル構築を競う時代に生きています。計算能力やアーキテクチャも重要ですが、真の競争優位性はトレーニングデータにあります。」
— サンディープ・チンチャリ(Story社 チーフAIオフィサー)
AIデータ領域のポテンシャルを探る:Scale AIの視点から
今月、AI業界で最も注目されたニュースの一つが、Metaによる巨額の資金投入です。マーク・ザッカーバーグ氏が中国人研究者を積極的に採用し、世界屈指のMeta AIチーム構築に乗り出しています。その中心となるのが、Scale AI創業者のアレクサンダー・ワン氏(28歳)です。ワン氏はScale AIをゼロから立ち上げ、現在同社の評価額は290億ドル。米国軍だけでなく、OpenAI、Anthropic、Meta自身など競合である業界大手にもサービスを提供しています。これらAIのリーディングカンパニーは、いずれもScale AIの大規模かつ高品質なラベル付きデータサービスを不可欠な基盤として活用しています。
Scale AIが突出したユニコーン企業になった理由
その核心は、AI産業における「データの役割」の重要性をいち早く見抜いた点にあります。
AIの技術スタックは、「計算力」「モデル」「データ」の3つが核となります。モデルは身体、計算力は栄養、データは知識や経験に相当します。
大規模言語モデルの台頭を契機に、業界の関心はモデルアーキテクチャから計算インフラへ移行しました。現在の大手モデルはほぼ例外なくトランスフォーマー型を標準構成とし、時折MoEやMoReなど新たなアーキテクチャも登場しています。主要プレイヤーは自社で超大規模計算クラスターを構築するか、AWSなどのハイパースケールクラウド事業者と長期契約を結んで計算リソースを確保しています。こうして計算基盤が整うと、次に重要となるのが「データ」です。
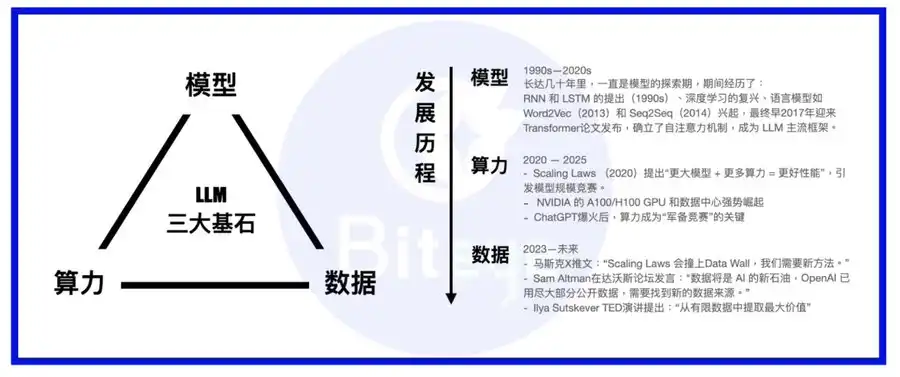
Palantirのような従来型エンタープライズデータ企業とは異なり、Scale AIはAIのための堅牢なデータ基盤構築に特化しています。単なる既存データセットの活用を超え、長期的なデータ生成にも注力し、専門家によるAIトレーナーチームを組織して、AIモデルに高品質なトレーニングデータを提供しています。
このビジネスモデルに納得できない方へ——モデルの学習プロセスをご紹介します
AIモデルの訓練は、「事前学習」と「ファインチューニング」の2段階から成ります。
事前学習は、赤ちゃんが言葉を覚える過程に似ており、AIがインターネット上の膨大なテキストやコードを取り込み、言語や基礎的なコミュニケーション能力を身につけるプロセスです。
ファインチューニングは、学校教育のように明確な正解がある形で進みます。学校がカリキュラムによって生徒を育てるように、用途別に設計・準備されたデータセットでAIモデルに特定スキルを習得させます。

ここまでお読みいただき、両タイプのデータの必要性をご理解いただけたと思います。
・一つは加工をほとんど必要としない大規模データ(量が重視)、主にRedditやTwitterなどのUGCプラットフォーム、オープンアクセスの学術リポジトリ、企業のプライベートデータセットなどから収集されます。
・もう一つは専門書のような、特定スキルや特質を身につけさせるために設計・厳選されたデータ。こちらは、データのクレンジング、フィルタリング、ラベリング、そして人によるフィードバックなどのステップが必要です。
この二つのグループがAIデータ市場の基盤を成しています。一見単純に見えるデータセットも、コンピュート拡大の法則が限界に達するにつれ、「データ」が大規模モデルベンダーにとって最大の差別化要因になるという考えが主流となっています。
モデルの進化が進むほど、より精緻で高度に特化したトレーニングデータがモデル性能の決定打となります。たとえるなら、モデルの訓練が武道家の育成だとしたら、データは極意書、コンピュートは霊薬、モデル本体は先天的な才能です。
垂直統合的な観点では、AIデータ産業は長期的に複利効果を享受できる分野です。初期に蓄積したデータ資産は時を経て価値が増し、複利的な収益を生み続けます。
Web3 DataFi:AIデータの究極の育成基盤
フィリピンやベネズエラなどでScale AIが展開する膨大なリモート・アノテーションと比べ、Web3にはAIデータ領域で「DataFi」という独自の強みがあります。
理想的なWeb3 DataFiの利点は次の通りです。
1. スマートコントラクトによるデータ所有権・セキュリティ・プライバシーの実現
公開データソースが枯渇し、未開拓・機密データの取得が喫緊の課題となっています。このタイミングで問われるのが「信頼のジレンマ」——あなたのデータを中央集約型事業者に売却するのか、それともIPをオンチェーン上で管理し、スマートコントラクトで誰が・いつ・何に使ったか透明に追跡するのか、という選択です。
機密性の高いデータには、ゼロ知識証明やTrusted Execution Environment(TEE)技術を活用し、「人」ではなく機械のみがデータにアクセスできるようにすることで、プライバシーと漏洩防止を両立できます。
2. 地理的アービトラージの内包:分散型参加によるグローバル人材の活用
従来のように安価な労働力を中央集約的にグローバルで探索するのではなく、Web3の分散設計とスマートコントラクトによる透明なインセンティブによって、多様なグローバル人材が公正な報酬のもとでデータに貢献できます。
ラベリングやモデル評価などのタスクも、分散型・非中央集権型アプローチのおかげで多様性を確保しバイアスを低減できるため、高品質なデータ獲得につながります。
3. ブロックチェーンによる透明なインセンティブと報酬設計
信頼性に欠ける従来運用を回避したい場合、ブロックチェーンのスマートコントラクトによってオープンかつコードベースで担保されたインセンティブが実現し、ブラックボックス的な手動運用を超えます。
地理的アービトラージを求めて各国に子会社設立するのは、グローバル化の後退下で難易度が増しています。オンチェーン決済を利用すれば、こうした障壁を回避し、国境を越えた参加や報酬支払いが効率的に行えます。
4. 効率的でオープンかつエンドツーエンドのデータマーケットプレイス
仲介手数料の存在は業界の永遠の課題です。中央集約型データ企業の代わりに、オンチェーンプラットフォームが透明なマーケットプレイスとなり、タオバオのように直接ユーザーと売り手を結びつけ、高い効率を実現します。
オンチェーンAIデータ需要は今後さらに細分化・複雑化しますが、分散型マーケットプレイスこそが効率的かつ大規模な需給マッチング・収益化を実現できます。
DataFiは一般投資家にとって最も参加しやすい分散型AI領域
AIツールの普及で参入障壁は下がりつつありますが、分散型AIが既存独占企業を崩そうとする現在、非技術者には依然としてハードルが高いプロジェクトも少なくありません。分散型計算ネットワークへの参加には高価なハードウェアが求められる場合もあり、モデル系マーケットプレイスでも使いこなすのが難しいことがあります。
一方で、Web3は一般ユーザーがAI革命の恩恵を直接受けられる貴重なチャンスを提供しています。搾取的なデータ労働契約は不要で、ウォレット接続だけで誰もがデータ貢献に参加可能です。データの提供、直感でのラベリング、モデル評価、シンプルなAIツールでのクリエイティブワークやデータ取引など、技術的ハードルはほぼなく、エアドロップ慣れしたユーザーには特に親和性が高いと言えます。
注目すべきWeb3 DataFiプロジェクト
資金が流れる先にトレンドが発生します。Scale AIによる143億ドルMeta投資やPalantir株価の5倍高騰はWeb2におけるDataFiの将来性を示し、Web3でもDataFi分野が有力な資金調達対象となっています。代表的な注目プロジェクトは以下の通りです。
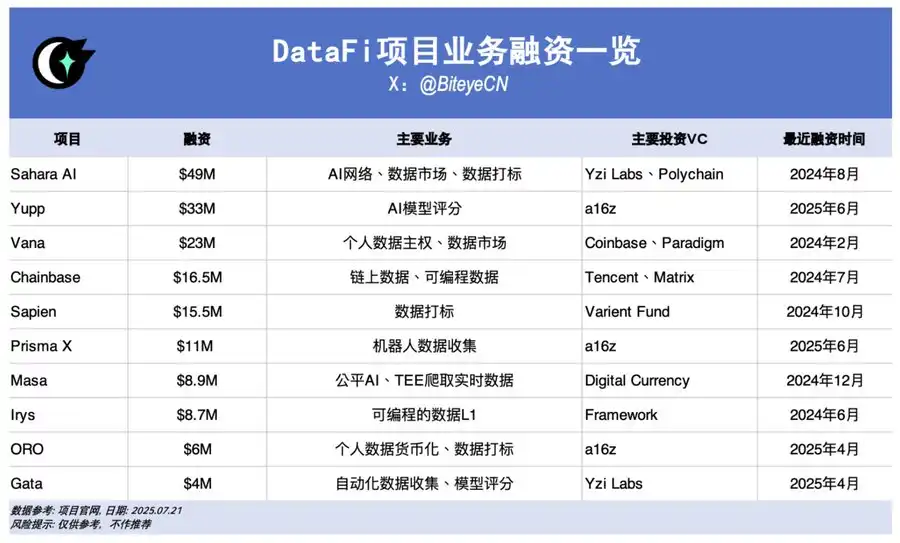
Sahara AI、@SaharaLabsAI、調達額:4,900万ドル
Sahara AIは分散型AIスーパーインフラとデータマーケットプレイスをビジョンに掲げています。Data Services Platform(DSP)β版は7月22日にローンチ予定で、データ提供やラベリング活動への報酬が得られます。
リンク:app.saharaai.com
Yupp、@yupp_ai、調達額:3,300万ドル
YuppはユーザーがAIモデルの出力を評価し、同一プロンプトへの回答を比較・投票するAIフィードバックプラットフォームです。獲得したYuppポイントはUSDC等のステーブルコインと交換できます。
リンク:https://yupp.ai/
Vana、@vana、調達額:2,300万ドル
VanaはウェブやSNSなどの個人データをデジタル資産化する仕組みを提供します。データはDataDAOやデータ流動性プールに集約されAIトレーニングに活用され、貢献者にはトークン報酬が支払われます。
リンク:https://www.vana.org/collectives
Chainbase、@ChainbaseHQ、調達額:1,650万ドル
Chainbaseはオンチェーンデータの構造化・収益化に特化し、200以上のブロックチェーンアクティビティをDApp開発者向け資産に変換します。データはManuscriptやTheia AIで処理・インデックス化されますが、リテール参加は現時点では限定的です。
Sapien、@JoinSapien、調達額:1,550万ドル
Sapienは人間の知識を高品質なAIトレーニングデータへと変換するプラットフォームで、誰でもデータのラベリングに参加できます。ピアレビューで品質を確保し、長期的な評判やステーキングにより報酬最大化を目指します。
リンク:https://earn.sapien.io/#hiw
Prisma X、@PrismaXai、調達額:1,100万ドル
Prisma Xはロボット向けオープン協調レイヤーの実現を目標とし、物理世界データの収集を主軸としています。初期段階ながら、ユーザーはロボットのデータ収集支援や遠隔操作、クイズ活動でポイント獲得に参加できます。
リンク:https://app.prismax.ai/whitepaper
Masa、@getmasafi、調達額:890万ドル
MasaはBittensorエコシステムにおけるデータ・エージェントサブネットをリード。データサブネットではTEEハードウェアを活用し、X/Twitterデータのリアルタイム取得が可能です。リテール向け参加は現状コスト・技術難易度ともに高めです。
Irys、@irys_xyz、調達額:870万ドル
IrysはAIおよびデータ集約型DApp向けの効率的・低コストなプログラマブルストレージと計算リソースを提供します。一般ユーザー向けのデータ貢献機会は限定的ですが、テストネットでは様々な参加施策が展開されています。
リンク:https://bitomokx.irys.xyz/
ORO、@getoro_xyz、調達額:600万ドル
OROは、SNS・ヘルスケア・フィンテック分野などの個人アカウント連携やデータタスクの達成で誰でもAI貢献者になれる仕組みを提供しています。テストネットは現在一般公開されています。
リンク:app.getoro.xyz
Gata、@Gata_xyz、調達額:400万ドル
分散型データレイヤーであるGataは、Data Agent(ブラウザ連動AIエージェント)、All-in-one Chat(Yuppタイプのモデル評価と報酬)、GPT-to-Earn(ChatGPTの対話収集向けブラウザ拡張)など3つの主要機能を提供しています。
リンク:https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
こうしたプロジェクトはどのように評価すべきか
現状、技術的障壁は低いものの、ユーザーやエコシステムのロイヤルティは短期間で積み上がります。早期のインセンティブやUX改善が極めて重要であり、多数のユーザーをいち早く集めたプラットフォームがデータ領域で大きな優位性を得る構造となっています。
人的リソースを要する事業ゆえ、データプラットフォームではワークフォース管理やデータ品質管理も不可欠です。多くのWeb3プロジェクトが直面している問題としては、短期的報酬を目当てとするユーザー(いわゆる「ファーマー」)が主流となり、悪質参加者が良質な貢献者を排除し、結果的にデータ品質が損なわれ、購入者離れを招くケースが挙げられます。SaharaやSapienなど先進的なプロジェクトでは、すでにデータ品質・貢献者との長期的な健全関係の構築に注力しています。
もう一つの課題は透明性です。ブロックチェーンの「不可能の三位一体」ゆえに、多くのプロジェクトが初期段階では中央集権的になりがちですが、Web3運用下でもオンチェーンデータ可視化やオープン性への本格的コミットメントが感じられないケースも少なくありません。これはDataFiエコシステムの長期健全性を損なうため、今後は「原点回帰」とオープン・透明化への積極的な進展に期待したいところです。
最後に、DataFi普及の鍵は二つです。AI経済の循環を支えるリテール層の大規模参加と、当面の収益源となる大手企業ユーザーの獲得——この両輪が揃ってはじめてデータエンジンが本格的に回ります。こうした領域でSahara AIやVanaなどはすでに堅調な成長を見せています。
まとめ
要するに、DataFiは人間の知恵によって機械知能を長期的に育成し、その貢献をスマートコントラクトで公正に報酬し、最終的に人間社会が機械知能の成長恩恵を享受することを目指す概念です。
AI時代に不安を抱く方や、暗号資産市場の変動の中でもブロックチェーン技術への信念を持ち続ける方にとって、DataFi参加は非常に賢明かつタイムリーな選択肢となるでしょう。
免責事項:
- 本記事は[BLOCKBEATS]からの転載であり、著作権は原著者[anci_hu49074, Biteye core contributor]に帰属します。転載に関するご相談はGate Learnチームまでご連絡ください。所定手続きに従い速やかに対応いたします。
- 免責事項:本記事の内容および意見は著者個人の見解であり、いかなる投資助言も含みません。
- 他言語版はGate Learnチームによる翻訳です。Gateの記載がない限り、無断での転載・配布・盗用を禁じます。
関連記事


ブロックチェーンについて知っておくべきことすべて

ステーブルコインとは何ですか?

流動性ファーミングとは何ですか?

Cotiとは? COTIについて知っておくべきことすべて
