Data as an Asset: DataFi Is Opening Up a New Blue Ocean
“We are living in an era where the world is competing to build the top foundational AI models. While compute power and architecture matter, the real moat is the training data.”
—Sandeep Chinchali, Chief AI Officer, Story
Exploring the Potential of the AI Data Sector: A Perspective from Scale AI
This month, one of the biggest stories in AI is Meta’s demonstration of significant financial resources, with Mark Zuckerberg on a talent-acquisition spree to build a world-class Meta AI team, heavily featuring Chinese researchers. At the helm is 28-year-old Alexander Wang, founder of Scale AI. Wang built Scale AI from the ground up—now valued at $29 billion—serving clients that include the US military as well as industry rivals like OpenAI, Anthropic, and Meta itself. These AI powerhouses all depend on Scale AI for data services, with Scale’s core business being the supply of massive, high-quality labeled data.
Why Did Scale AI Emerge as a Standout Unicorn?
The key is its early realization of data’s central role in the AI industry.
Compute, models, and data are the three pillars of the AI stack. Think of the model as the body, compute as the food, and data as the knowledge and experience.
Since the rise of large language models, industry priorities have shifted from model architecture to compute infrastructure. Most leading models have adopted transformers as the standard architecture, with periodic innovations like MoE or MoRe. Major players either build their own superclusters for compute or sign long-term contracts with hyperscale cloud providers like AWS. With compute secured, the spotlight has turned to the rising importance of data.
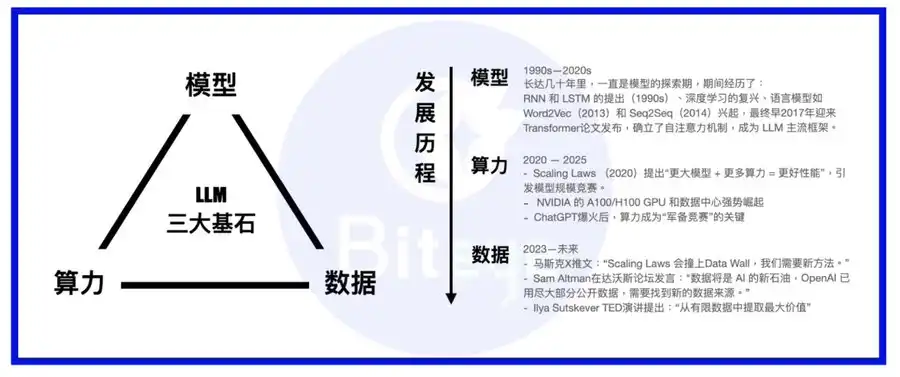
Unlike established enterprise data companies like Palantir, Scale AI is dedicated to building a robust data foundation for AI. Its business goes beyond mining existing datasets; it’s focused on long-term data generation, assembling AI trainer teams of human subject-matter experts to deliver higher-quality training data for AI models.
Not Convinced by This Business? Let’s See How Models Are Trained.
Training an AI model involves two stages—pre-training and fine-tuning.
Pre-training is similar to how a baby learns to speak: the AI ingests massive amounts of text and code scraped from the internet to learn natural language and basic communication.
Fine-tuning mirrors formal education, with clear right and wrong answers. Just as schools shape students based on their curriculum, we use tailored, well-prepared datasets to train models with specific capabilities.

By now you’ve likely realized we need both types of data:
· One type requires minimal processing—quantity is key. These are typically web-scraped datasets from major user-generated content platforms (Reddit, Twitter), open-access literature repositories, or corporate private datasets.
· The other is akin to specialized textbooks—carefully designed and curated to impart particular skills or qualities. This category involves data cleaning, filtering, labeling, and human feedback.
Together, these two groups form the backbone of the AI data market. While datasets may seem simple technologically, dominant thinking holds that as compute scaling laws reach their limits, data will become the critical differentiator for large model vendors.
As models continue to advance, increasingly fine-grained and specialized training data will become the key factor determining model performance. Stretching the analogy, if model training is like raising a martial arts master, data is the ultimate training manual—while compute is the magic elixir and the model itself is the innate talent.
From a vertical perspective, AI data is a long-term compounding sector. As early work accumulates, data assets generate compounding returns—growing more valuable with age.
Web3 DataFi: The Ultimate Breeding Ground for AI Data
Compared to Scale AI’s huge remote annotation workforce in countries like the Philippines and Venezuela, Web3 has unique advantages in the AI data space—introducing the concept of DataFi.
Ideally, the advantages of Web3 DataFi include:
1. Data Ownership, Security, and Privacy via Smart Contracts
With public data sources nearing exhaustion, acquiring untapped and even private data has become critical. This brings the trust dilemma: Sell your data outright to a central aggregator, or keep your IP on-chain, maintaining ownership and using smart contracts to transparently track who, when, and for what your data is used?
For sensitive data, technologies like zero-knowledge proofs and Trusted Execution Environment (TEE) hardware can ensure that only machines see your information, preserving privacy and preventing leaks.
2. Built-in Geographic Arbitrage: Distributed Participation Attracts the Best Global Talent
It’s time to rethink traditional labor models. Instead of a centralized global search for cheap labor as Scale AI does, Web3’s distributed design—plus transparent, smart-contract incentives—lets a diverse, global workforce contribute data and get paid fairly.
For tasks like labeling or model validation, a distributed, decentralized approach supports greater diversity and reduces bias—an important advantage for high-quality data.
3. Transparent Incentives and Settlements via Blockchain
Want to avoid unreliable operations? Blockchain’s smart contracts enable open, code-enforced incentives—outperforming black-box manual systems.
As globalization recedes, achieving low-cost geographic arbitrage by opening companies everywhere is increasingly difficult. On-chain settlement lets you bypass these barriers and streamline cross-border participation and payout.
4. Efficient, Open, End-to-End Data Marketplaces
Middlemen taking a cut is a perpetual pain point. Instead of a centralized data company, on-chain platforms can serve as transparent, Taobao-like marketplaces directly connecting buyers and sellers for maximum efficiency.
The demand for on-chain AI data will only grow more segmented and complex, and only a decentralized marketplace can efficiently meet and monetize that need at scale.
DataFi Is the Most Accessible Decentralized AI Play for Retail Users
While AI tools have made entry easier and decentralized AI aims to disrupt today’s incumbent monopolies, it’s undeniable that many projects are still out of reach for non-technical users. Participating in decentralized compute networks often requires expensive hardware, while model marketplaces can feel daunting.
In contrast, Web3 provides rare, accessible opportunities for everyday users in the AI revolution. No need for exploitative data-labor contracts—users can connect their wallets to participate. You can provide data, label model outputs using intuition, evaluate models, or use simple AI tools for creative work and data transactions—often with zero technical barrier for airdrop veterans.
Top Web3 DataFi Projects to Watch
Where the money goes, the trend follows. Scale AI’s $14.3 billion Meta investment and Palantir’s fivefold stock jump have shown DataFi’s promise in Web2; in Web3, DataFi stands out in fundraising. Here are some notable projects:
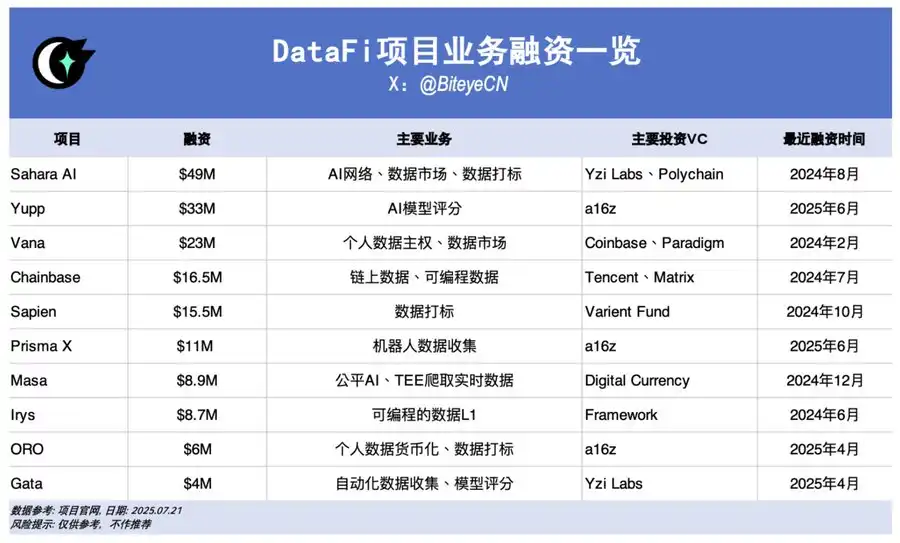
Sahara AI, @SaharaLabsAI, raised $49 million
Sahara AI’s vision is a decentralized AI super-infrastructure and data marketplace. Its Data Services Platform (DSP) beta goes live July 22, rewarding users for data contributions and labeling.
Link: app.saharaai.com
Yupp, @yupp_ai, raised $33 million
Yupp is an AI feedback platform where users assess AI model outputs, comparing responses to the same prompt and voting for the best. Earned Yupp points can be converted to stablecoins like USDC.
Link: https://yupp.ai/
Vana, @vana, raised $23 million
Vana lets users turn personal data—such as browsing and social activity—into digital assets. Data is pooled in DataDAOs and Data Liquidity Pools for AI training, with token rewards for contributors.
Link: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, raised $16.5 million
Chainbase focuses on on-chain data, structuring activity from over 200 blockchains into monetizable assets for DApp developers. Data is indexed and processed using its Manuscript system and Theia AI. Retail participation is currently limited.
Sapien, @JoinSapien, raised $15.5 million
Sapien converts human knowledge at scale into top-tier AI training data. Anyone can label data on its platform, with quality enforced via peer review. Long-term reputations and staking are encouraged to maximize rewards.
Link: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, raised $11 million
Prisma X aims to be the open coordination layer for robots, with physical data collection a central pillar. Still in early stages, users can participate by supporting robot data collection, remote operation, or quiz activities for points.
Link: https://app.prismax.ai/whitepaper
Masa, @getmasafi, raised $8.9 million
Masa leads in the Bittensor ecosystem with its data and agent subnets. The data subnet offers real-time access via Trusted Execution Environment (TEE) hardware that collects X/Twitter data. Currently, retail participation is costly and complex.
Irys, @irys_xyz, raised $8.7 million
Irys targets efficient, low-cost programmable data storage and compute for AI and data-rich DApps. While user data contribution opportunities are limited, the current testnet phase has multiple participation activities.
Link: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, raised $6 million
ORO empowers anyone to contribute to AI—by linking personal (social, health, or fintech) accounts or completing data tasks. The testnet is now open to participants.
Link: app.getoro.xyz
Gata, @Gata_xyz, raised $4 million
As a decentralized data layer, Gata currently offers three key products: Data Agent (browser-activated AI agents), All-in-one Chat (model evaluation rewards, Yupp-style), and GPT-to-Earn (browser extension for collecting ChatGPT conversations).
Link: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
How Should We Evaluate These Projects?
Currently, technical barriers for these projects are quite low, but user and ecosystem stickiness compounds quickly. Early investment in incentives and user experience is vital: only by attracting enough users can a platform win big in data.
As labor-intensive ventures, data platforms must also address workforce management and data quality. Many Web3 projects face the common problem that a majority of users are motivated solely by short-term gains—so-called “farmers”—often at the expense of quality. If this continues, bad actors will crowd out quality contributors, undermining data integrity and deterring buyers. Sahara, Sapien, and others already prioritize data quality and are working to build long-term, healthy relationships with contributors.
Another issue is a lack of transparency. Blockchain’s “impossible trinity” often means projects start out more centralized, but many projects still look like projects that retain Web2 characteristics despite operating in a Web3 environment—with little on-chain data visible and unclear commitment to openness. This poisons the long-term health of DataFi. We hope more teams stay true to their roots and accelerate progress toward openness and transparency.
Finally, DataFi’s path to mass adoption requires two prongs: attracting enough retail (consumer) participants to fuel the data engine and create a closed AI economy, and earning the business of leading enterprises, which remain the main revenue source in the near term. Here, Sahara AI, Vana, and related projects have made solid headway.
Conclusion
In the end, DataFi is about harnessing human intelligence to cultivate machine intelligence over the long term—using smart contracts to ensure that human contributions are rewarded, and ultimately allowing people to benefit from the growth of machine intelligence.
For those experiencing uncertainty in the AI era or maintaining confidence in blockchain technology amid cryptocurrency market fluctuations, participating in DataFi may be a prudent and timely choice.
Disclaimer:
- This article is reprinted from [BLOCKBEATS], copyright to the original author [anci_hu49074, Biteye core contributor]. For reprint issues, please contact the Gate Learn Team for prompt resolution following relevant procedures.
- Disclaimer: The opinions expressed in this article are solely those of the author and do not constitute investment advice.
- Other language versions were translated by the Gate Learn Team. Without specific mention of Gate, no translation may be reproduced, distributed, or plagiarized.
Related articles

Solana Need L2s And Appchains?

Sui: How are users leveraging its speed, security, & scalability?

The Future of Cross-Chain Bridges: Full-Chain Interoperability Becomes Inevitable, Liquidity Bridges Will Decline

What Is Ethereum 2.0? Understanding The Merge

Navigating the Zero Knowledge Landscape
